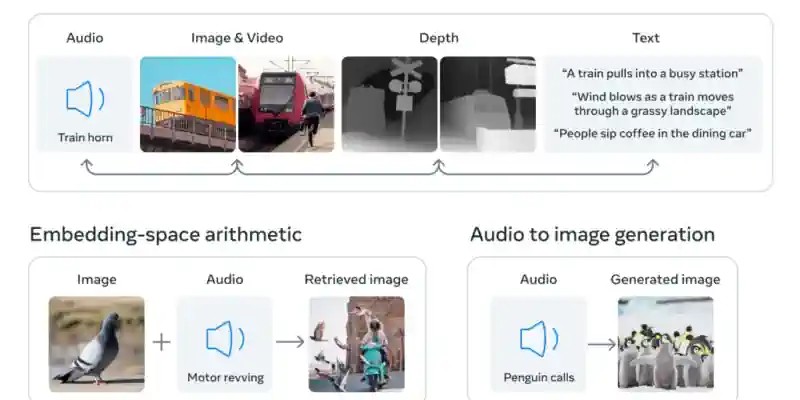
У новаторській розробці Meta представила ImageBind, інноваційну модель штучного інтелекту, яка долає розрив між машинами та людьми з точки зору цілісного навчання за допомогою багатьох модальностей. На відміну від традиційних систем штучного інтелекту, які покладаються на конкретні вбудовування для кожної модальності, ImageBind створює спільний простір представлення, що дозволяє машинам одночасно вивчати текст, зображення/відео, аудіо, одиниці вимірювання глибини, термічні та інерційні вимірювання (IMU). У цій статті досліджується величезний потенціал ImageBind і його значення для майбутнього штучного інтелекту.
ImageBind являє собою значний крок вперед у можливостях штучного інтелекту, долаючи обмеження попередніх спеціалізованих моделей, навчених індивідуальним модальностям. Включаючи численні сенсорні входи, ImageBind пропонує машинам комплексне розуміння, яке поєднує різні аспекти інформації. Наприклад, Make-A-Scene від Meta може використовувати ImageBind для створення зображень на основі аудіо, дозволяючи створювати захоплюючі враження, такі як тропічні ліси чи галасливі ринки. Крім того, ImageBind відкриває двері для більш точного розпізнавання вмісту, модерації та креативного дизайну, включаючи безперебійне створення медіафайлів і розширені функції мультимодального пошуку.
Як частина ширших зусиль Meta з розробки мультимодальних систем штучного інтелекту, ImageBind закладає фундамент для дослідників, щоб досліджувати нові кордони. Здатність цієї моделі поєднувати 3D-сенсори та сенсори IMU може революціонізувати дизайн та враження від захоплюючих віртуальних світів. Крім того, ImageBind пропонує багатий шлях для дослідження спогадів, уможливлюючи пошук у різних модальностях, таких як текст, аудіо, зображення та відео.
Створення спільного простору для вбудовування багатьох модальностей давно є проблемою в дослідженнях ШІ. ImageBind обходить цю проблему, використовуючи широкомасштабні моделі візуальної мови та використовуючи природні пари з зображеннями. Вирівнюючи модальності, які виникають разом із зображеннями, ImageBind плавно поєднує різноманітні форми даних. Модель демонструє потенціал цілісної інтерпретації вмісту, дозволяючи різним модальностям взаємодіяти та встановлювати значущі зв’язки без попереднього спільного навчання.
Унікальна поведінка масштабування ImageBind показує, що його продуктивність покращується з більшими моделями зору. Завдяки самостійному навчанню та використанню мінімальних навчальних прикладів модель демонструє нові можливості, такі як зв’язування аудіо та тексту або прогнозування глибини за зображеннями. Крім того, ImageBind перевершує попередні методи в задачах класифікації аудіо та глибини, досягаючи значного підвищення точності та навіть перевершуючи спеціалізовані моделі, навчені виключно цим модальностям.
Завдяки ImageBind Meta прокладає шлях для машин, щоб навчатися з різноманітних модальностей, штовхаючи штучний інтелект у нову еру цілісного розуміння та мультимодального аналізу. Компанія досягла значних успіхів у сфері штучного інтелекту, і деякий час тому компанія запустила власну модель штучного інтелекту.








